How to Improve AI Chatbot Accuracy
Created: 10/04/2026

A few years back, a mid-sized e-commerce brand launched a support chatbot they were proud of. It answered shipping questions, handled returns, and pulled order data in real time. The team celebrated.
Six months later, customer satisfaction scores had barely moved. When they dug into the transcripts, they found the bot was right about 60% of the time. Good enough to seem helpful, bad enough to quietly erode trust. Users would get one wrong answer, then call support anyway.
This is the accuracy trap. Chatbots that are mostly right are often worse than no bot at all because they create a false sense of resolution.
Improving accuracy isn't one fix. It's a set of decisions made at each stage of how your bot is built, trained, and maintained. Let's go through each one.
Start With the Right Kind of Data
Most chatbot accuracy problems start in the training data. Teams pull whatever they have - old support tickets, FAQs, documentation - and assume the model will sort it out. It won't.
Garbage in, garbage out is especially true here. A bot trained on outdated policy documents will confidently state policies that changed two years ago. A bot trained on tickets where agents used casual shorthand will give incomplete answers to precise questions.

Get Intent Recognition Right
Intent recognition is the bot's first decision: what is this person actually asking? Get it wrong here and nothing downstream matters.
The common failure is overbroad intent categories. When "billing" covers cancellations, refund requests, payment method changes, and invoice downloads, the bot has no idea which path to take. It guesses, and guessing looks like accuracy until you check the outcomes.

Break intents down until each one maps to a clear action the bot can actually take. If an intent doesn't have a defined resolution path, it's not ready to be trained.
Also: build a strong fallback. When the bot isn't sure, it should say so cleanly. "I'm not sure I understood that correctly - were you asking about X or Y?" is far better than a confident wrong answer.
Context Is the Difference Between a Good Answer and the Right Answer
Single-turn accuracy is the easy version of the problem. The harder version is maintaining accuracy across a conversation - when the user references something they said three messages ago.
"Actually, change that to the blue one" means nothing if the bot doesn't remember they were talking about a jacket in size medium that ships to a specific zip code.

Retrieval-Augmented Generation: Real Answers From Real Sources
If your chatbot is built on a large language model, one of the biggest accuracy improvements you can make is adding retrieval-augmented generation (RAG). Instead of relying purely on what the model learned during training, RAG pulls answers from your actual knowledge base at query time.
This matters enormously for factual accuracy. The model can't hallucinate a policy if it's reading the policy document when it answers.
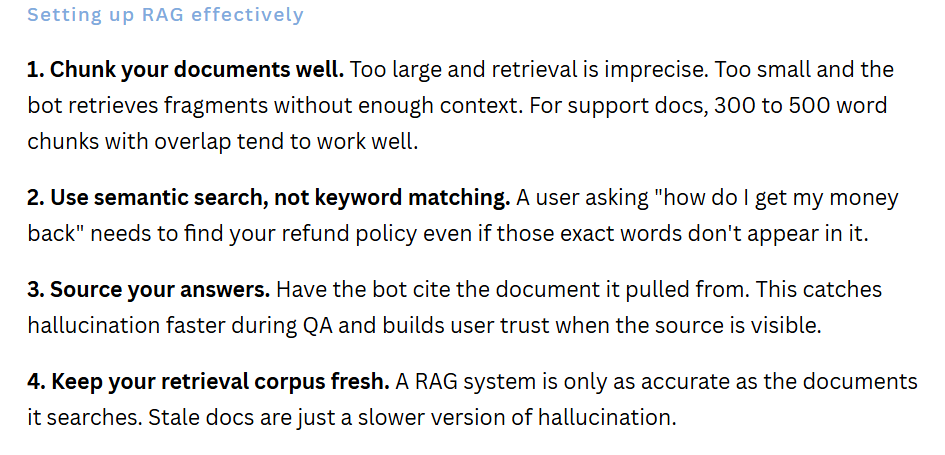
Measure What Actually Matters
Most teams track metrics that feel like accuracy but aren't. Deflection rate tells you how often users didn't escalate. It doesn't tell you if they got the right answer. CSAT tells you if users were satisfied. Satisfied with an incorrect answer still counts as satisfied.

Build a dashboard that shows these together. A bot with high containment and high fallback rate is probably just confidently wrong. You want high containment paired with low incorrect answer rate - those two moving in the same direction is the signal you're improving.
The Feedback Loop That Most Teams Skip
Once a bot is live, it starts generating more useful training data than anything you created before launch. The conversations themselves show you exactly where accuracy breaks.
But most teams treat post-launch data as a support problem, not a training opportunity. Escalated conversations go to agents. Negative ratings go to a spreadsheet. The model stays the same.
Flag low-confidence responses automatically.
When the bot's confidence score falls below a threshold, log the conversation for review - not just the ones that escalate.
Tag failure modes in escalations
Wrong answer, missing answer, misunderstood intent, tone issue - each gets a category. Monthly, review the distribution. Train on the biggest buckets first.
A/B test prompt changes
Before rolling out a new intent handler or system prompt change, run it against a control on a slice of traffic. Accuracy improvements in QA don't always hold in production.
Set a monthly retraining schedule
Chatbots decay. The world changes, your product changes, and user language shifts. A bot trained in January 2025 without updates will be noticeably worse by January 2026
"Post-launch conversations are the best training data you'll ever have. Most teams let them go to waste."
Prompt Engineering for LLM-Based Bots
If your bot is powered by an LLM, the system prompt is one of the highest-leverage things you control. A vague prompt produces vague answers. A precise, well-scoped prompt produces consistent, accurate responses.
What belongs in a production system prompt:
Role and scope.
Tell the model exactly what it is and what it's allowed to answer. "You are a support assistant for [Company]. Only answer questions about orders, products, and account management."
What to do when uncertain
"If you don't know the answer, say so and offer to connect the user with a support agent." Without this, models fill gaps with guesses.
Format constraints
"Keep answers under 3 sentences unless the user asks for details." Shorter answers are more likely to be accurate because there's less surface area for error.
Escalation triggers
List the situations that should always go to a human: legal questions, billing disputes above a threshold, and account security issues
Test your system prompt against a bank of 50 to 100 challenging questions before each update. Keep the versions in version control. When accuracy regresses, you want to know what changed.
One More Thing: Don't Automate What Isn't Understood
Chatbot accuracy failures often stem from a business problem, not a technical one. Teams automate use cases before they fully understand how those conversations go. They write scripts for how they want users to ask questions, not how users actually ask them.
Before training any new intent, spend two weeks reading every transcript where a human agent handled that topic. Note the exact language users use, where they get confused, what information they need before they feel satisfied. Then build the intent around that reality.
The best-performing chatbots aren't the ones with the most intents. They're the ones that handle a smaller set of topics so well that users stop noticing they're talking to a bot.
That's the actual goal.

Improve Your Chatbot Accuracy
Fix wrong answers and improve response quality with simple, proven steps. Learn how to use real user data, refine your knowledge base, and guide your bot to give clear, reliable replies.